| Porting my blog for the second time, images part 3 |
Porting my blog for the second time, images part 5 |
Porting my blog for the second time, images part 4
This is post #11 of my series about how I port this blog from Blogengine.NET 2.5 ASPX on a Windows Server 2003 to a Linux Ubuntu server, Apache2, MySQL and PHP. A so called LAMP. The introduction to this project can be found in this blog post https://www.malmgren.nl/post/Porting-my-blog-for-the-second-time-Project-can-start.aspx.
In my previous post I programmed my perl program so that it carried out the finding of URLs and replacing them with place holders. Now I will start downloading images. So I search this in google "use perl to download images from internet". And from the pages found I will try the methods described in this page: http://www.perlmonks.org/?node_id=963858. A popular package for doing this is LWP::Simple. I think it supposed to be simple to use. So first we need to get it into my Ubunto server. So I type apt-get install liblwp-simple-perl. Fail. So then I start thinking that maybe it is part of a bigger package LWP? After several rounds of trial and error I try this apt-get install libwww-perl and then Ubunto tells me it is already installed and up to date. So simple! I don't believe it can be that easy so I make myself a little test program.
use LWP::Simple;
my $data = LWP::Simple::get('http://4.bp.blogspot.com/-YBd8oEO4eIg/Tf-kL-V3UfI/AAAAAAAAAGc/fUZCfHzpVoc/s1600/PICT1911.JPG');
my $imageFilename = "/usr/local/bin/images/image.jpg";
open (FH, "≻$imageFilename");
binmode (FH);
print FH $data;
close (FH);
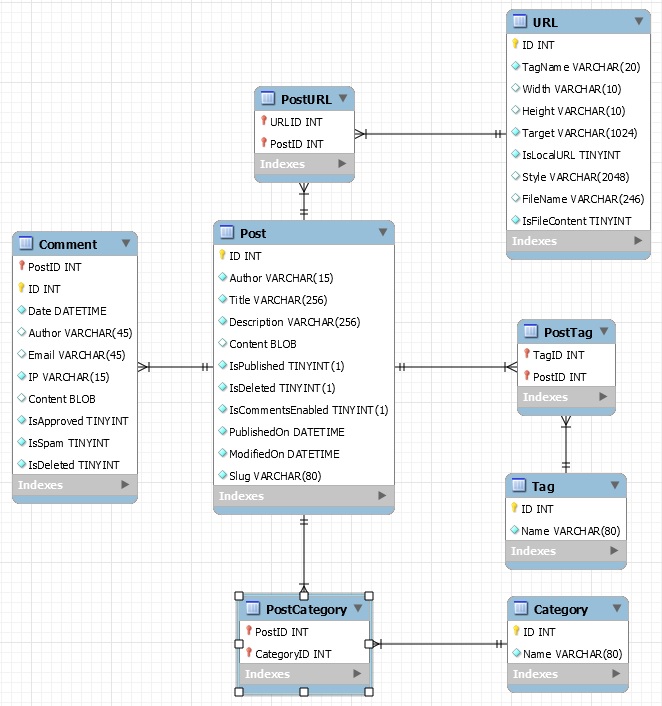
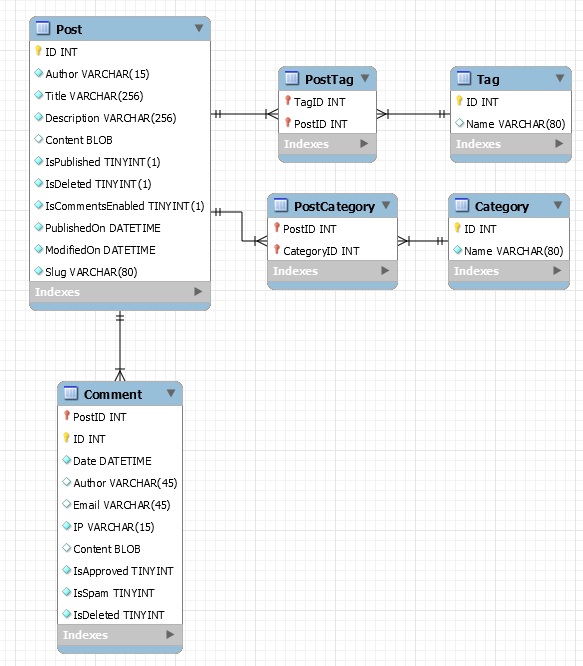
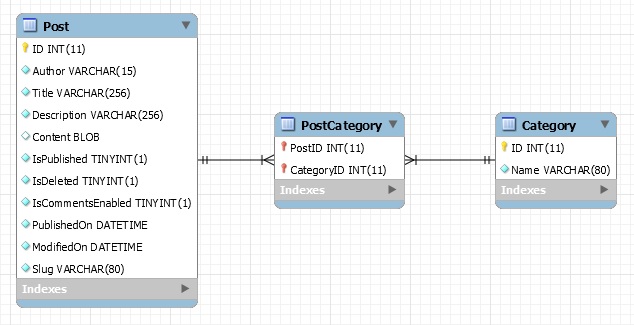
Sure enough, the image is downloaded and saved to the directory '/usr/local/bin/images/image.jpg'. It simply works. So are we ready to roll? Well if you recall the listing in this post https://www.malmgren.nl/post/Porting-my-blog-for-the-second-time-images-part-1.aspx then you might remember that the filename was for example
PICT2243.JPGbut the exact same filename was used also for the high resolution version and the only difference was that the lowres version had s200 in the link and the high res version had s1600. Now I would like to store the images in one directory and although database IDs are magnificent it is much nicer for me to have something more human readable.

If I put the Blogger and Picasa width indicator and puts it between the original filename and the extension then I can store all sizes of the image in the same directory.
Assumptions assumptions. Whenever I did not use Blogger and Picasa I uploaded the files directly to my old server and in that case the filenames where such that I could store the same file in the same directory.
# Change the image filename to indicate the resolution of the image.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-images-part-4.aspx
$strFileName = $strTarget;
if ($strFileName =~ s/(.*?\/)(s[0-9]+)(\/)([a-z0-9]+)(\.[a-z]{3,4})$/$4_$2$5/i)
{
print "Transformed filename: " . $strFileName . "\n";
}
else
{
$strFileName = $strTarget;
$strFileName =~ s/(.*?\/)([^\/]+$)/$2/;
}
To begin with I get a copy of the entire $strTarget variable that I talked about in my previous blog. Then I carry out a search and replace. A search and replace is done with the s/ ... / ... /i construction. The initial s stands for search and the last i says that the search is case insensitive. The first part is the search and the second is the replacement. To search for a slash I need to escape it with a backslash so that Perl is not confused with what belongs to the s///i expression. For the rest it is regular expression syntax. I will not start explain that in depth here because then it will cost me my entire evening. If you are interested search for perlre in google.
The result of this search and replace is what I showed in the image here above.
So are we ready to roll? No not yet. I would like to to download images etc of my own material that I want to host myself. I decided that if the link pointed to my own domain or blogger or googleusercontent then it is a candidate for download but only if it is a jpg, gif, pdf or png. Soon I have my files back home, I am delighted. Added these two checks at the beginning of the content processing loop.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-images-part-4.aspx $bIsLocalURL = $tag =~ /\.(malmgren\.nl|blogspot\.com|googleusercontent\.com)/i; $bIsFileContent = $tag =~ /\.(pdf|jpg|gif|png)/i;
Then after all the replacement of URLs the first round I can download the images. Like this:
# Is the URL pointing to a file to be downloaded?
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-images-part-4.aspx
if ($bIsLocalURL && $bIsFileContent)
{
print "Get target " . $strTarget . " save to " . $strFileName . "\n";
my $data = LWP::Simple::get($strTarget);
my $imageFilename = "/usr/local/bin/images/" . $strFileName;
open (FH, "≻$imageFilename");
binmode (FH);
print FH $data;
close (FH);
}
So this means I actually can download the images. Yet no capcha. So now I can finish this image business and insert the URL data in the database. But that is for next time.










 Sounds in the blogsystemNext version of the slideshowLearning Python Part IIILearning Python Part IIImpressionism and beyond. A Wonderful Journey 28 January 2018Fixing unresolved links after editingThis is my summer 2016 blog!Porting my blog for the second time, linksPorting my blog for the second time, editing part 7Porting my blog for the second time, editing part 6Porting my blog for the second time, categories part 3Business cards, version 1Porting my blog for the second time, deployment part 2Not indexed but still missing? Google hypocrisy.A new era: Nikon D5100 DSLR, Nikkor 18 - 55 and 55 - 300!
Sounds in the blogsystemNext version of the slideshowLearning Python Part IIILearning Python Part IIImpressionism and beyond. A Wonderful Journey 28 January 2018Fixing unresolved links after editingThis is my summer 2016 blog!Porting my blog for the second time, linksPorting my blog for the second time, editing part 7Porting my blog for the second time, editing part 6Porting my blog for the second time, categories part 3Business cards, version 1Porting my blog for the second time, deployment part 2Not indexed but still missing? Google hypocrisy.A new era: Nikon D5100 DSLR, Nikkor 18 - 55 and 55 - 300! I moved from Sweden to The Netherlands in 1995.
I moved from Sweden to The Netherlands in 1995.
Here on this site, you find my creations because that is what I do. I create.