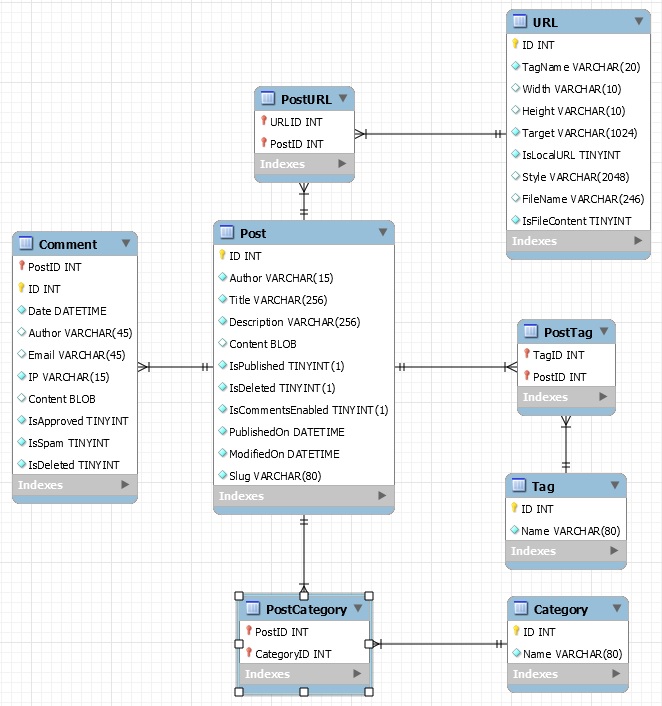
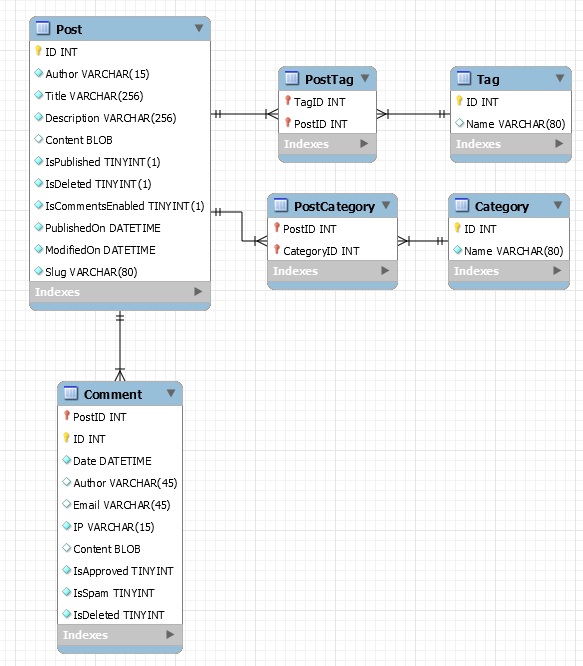
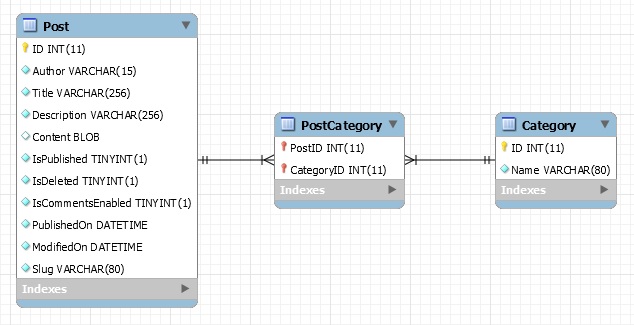
| Porting my blog for the second time, images part 2 |
Porting my blog for the second time, images part 4 |
Porting my blog for the second time, images part 3
This is post #10 of my series about how I port this blog from Blogengine.NET 2.5 ASPX on a Windows Server 2003 to a Linux Ubuntu server, Apache2, MySQL and PHP. A so called LAMP. The introduction to this project can be found in this blog post /post/Porting-my-blog-for-the-second-time-Project-can-start.
In my previous two posts I explained why I want to download my own images and how I am going to store the images but there is no single image downloaded yet and it is very likely that when Blogger and Picasa finds out what I am trying to do they most probably will throw captchas at me. And if this is not enough, how am I going to do it? I still have no idea. But for the rest things progress nicely.
When I am able to print the data to the console output then I can also by now insert it to the database. So I work on the part of my program loading a post and parsing it to find the URLs and print them to the console output. The method I use here is that I find a sample of an XML that I try to parse to get the data out of it the way I want so I need to find representative examples of how data looks like so that my program can handle most cases. For this I have to search through the old XML files and while doing this I noticed that I have internal links in my blog that points to posts as if this blog was still hosted at Blogger. This management of URLs will be really useful for me.
In the database I want the URLs to be readable, no special escape characters %20 and what not. To do that I will use the URI::Encode package (http://search.cpan.org/~mithun/URI-Encode-v1.0.1/lib/URI/Encode.pm) and inside this package there is a decode function. Do you remember how to get a Perl package on an Ubuntu server? Nope. I wrote about it in this post /post/Porting-my-blog-for-the-second-time-walk-the-old-data. The command on the linux shell is 'apt-get install liburi-encode-perl'. At first I did not notice that the package was named uri so I was trying url several times but 'i' and 'l' is not the same letter! Pfff... Added this line at the top of my Perl program:
use URI::Encode qw(uri_encode uri_decode); #apt-get install liburi-encode-perl
An URL that looks like this:
http://www.jens.malmgren.nl/Brief%20Explanation%20of%20Music%20Theory.pdf
After decoding it looks like this:
http://www.jens.malmgren.nl/Brief Explanation of Music Theory.pdf
Much more readable.
While we are at it you notice that I sometimes make links where the link text is the same as the link. Later when I am done with this porting process I don't want the link texts to be broken old links, I want them to be identical to the href attribute. But how am I going to do this? Take this very post you are reading right now as an example. Here in the text above I am talking about URLs but they are NOT links! And elsewhere there are links. The solution I will use is to first find URLs as attributes of tags. All these URLs I will then transform to the form {URL :134} as I mentioned earlier. Then I go over the text one more time searching for URLs I already found in that same post and convert these as well. Here below is the first routine processing the URLs the first time:
# Replace an URL with an URL place holder. Store the URL in dictURLToDatabaseID so that
# later on it is possible to search for URLs a second time.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-images-part-3.aspx
my $iDatabaseIDofThisURLentry = $iUrlCount;
if ($tag =~ /(.*?)(http|https)(://.+?)["']/i)
{
my $strParsedURL = $2.$3;
$strTarget = uri_decode($strParsedURL);
$dictURLToDatabaseID{$strTarget} = $iDatabaseIDofThisURLentry;
$tag =~ s/^(.*?)($strParsedURL)(.*?)$/$1{URL:$iDatabaseIDofThisURLentry}$3/;
}
Since I have not started inserting the URLs into the database I need to simulate that I have an ID for the URL record and I do that with the URL count variable on line 1. Later on I will create the URL record and get the ID of it here.
At line 2 I parse the tag content. First in (.*?) comes the text before the URL and then in (http|https) there starts the URL and it ends right before a single quote or double quote. So the second and third parenthesis is my URL.
On line 4 these second and third parenthesis goes into a new variable called $strParsedURL. That URL we decode and save for insertion into the database. Since we at this time already will have the record I will need to update an existing record with the $strTarget value.
On line 6 we store the URL and database ID key value pair in the %dictURLToDatabaseID dictionary. After converting the whole post we will get back to these.
On line 7 we replace the URL with the URL place holder such as {URL :134}. This is done with help of a search replace in the tag where we search for the URL we already found and the things in front and after are stored in separate sub search expressions. In the replace we then recall these sub search sections with $1 and $3 and put the place holder in the middle.
After the first pass of processing the post we need to go over the post again for the display values like here below:
# Post processing the content of the post to find any remaining URLs in the text.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-images-part-3.aspx
foreach my $strParsedURL ( keys %dictURLToDatabaseID )
{
print "URL: $strParsedURL, DatabaseID: $dictURLToDatabaseID{$strParsedURL}
";
$contentResult =~ s/$strParsedURL/{URL:$dictURLToDatabaseID{$strParsedURL}}/g;
}
Here is a loop over the keys in the dictURLToDatabaseID hash table. For every key we search for the URL and replace this with the place holder. The variable $contentResult holds the text of the entire post.
This is it for this time. I still have not started on downloading any images. Will I start on that the next time?











 Sounds in the blogsystemNext version of the slideshowLearning Python Part IIILearning Python Part IIImpressionism and beyond. A Wonderful Journey 28 January 2018Fixing unresolved links after editingThis is my summer 2016 blog!Porting my blog for the second time, linksPorting my blog for the second time, editing part 7Porting my blog for the second time, editing part 6Porting my blog for the second time, categories part 3Business cards, version 1Porting my blog for the second time, deployment part 2Not indexed but still missing? Google hypocrisy.A new era: Nikon D5100 DSLR, Nikkor 18 - 55 and 55 - 300!
Sounds in the blogsystemNext version of the slideshowLearning Python Part IIILearning Python Part IIImpressionism and beyond. A Wonderful Journey 28 January 2018Fixing unresolved links after editingThis is my summer 2016 blog!Porting my blog for the second time, linksPorting my blog for the second time, editing part 7Porting my blog for the second time, editing part 6Porting my blog for the second time, categories part 3Business cards, version 1Porting my blog for the second time, deployment part 2Not indexed but still missing? Google hypocrisy.A new era: Nikon D5100 DSLR, Nikkor 18 - 55 and 55 - 300! I moved from Sweden to The Netherlands in 1995.
I moved from Sweden to The Netherlands in 1995.
Here on this site, you find my creations because that is what I do. I create.