| Portrait of Elsie Luna |
Susanne 1 December |
Learning Machine Learning and Artificial Intelligence, Part 3
This episode is huge. It contains much math. In the end there is my entire program for parsing word documents with Python. To be TOTALLY HONEST with you, I write this more for myself than I write it for you. If you are a more casual visitor I would go to other pages of this site. They are usually lighter.
Monday 16 September 2019
Since Friday there has been a lot going on with our new house. Much of the Saturday, we worked on the mortgage forms. The bank wants us to fill in all sorts of information, and give them information. That took much of the Saturday. The road society has got the statutes and “household rules” approved by the municipality. We just need to vote if all members are approving these, and then the society can be official. Perhaps this takes place on Thursday this week. We ordered electricity and water for the house. That will take a really long time to get, so we better do it now.
We also went to the site to have a look. I had programmed the location into Google maps. I created a MyMap. I could walk in the field and gauge in the borders of the future plot with the GPS of my phone. It is huge!
With all that behind me, it is time for AI and ML from the book Hands-On Machine Learning with Scikit-Learn & TensorFlow by Aurélien Géron.
At the end of the previous blog post (Part 2), there was the confusion matrix of multi-class classification. I wonder if there exist all sorts of formulas for quality measurements for the confusion-matrix like there was for the confusion matrix of binary classes?
This was just a reflection. I leave the end of chapter three a little untouched, it is time to move on!
Chapter four!
So far, we treated ML models like black boxes. No way, you are kidding me!? That is an understatement. It has been frustrating for me to read one hundred and six pages about black boxes. Apparently, I built a spam classifier from scratch during that time. I cannot recall doing that. The image classification I do remember. Going back to the book, I cannot find any spam classifier. I might be mistaken.
So with this intro to chapter four, we get a faint hope that the author will let us know how things are taking place inside the black boxes. We begin with linear regression analysis. Okay, amaze me.
I studied maths at the Uni. That math is rusty, to say the least. They tell me what I need to know in this chapter. They also tell me that if I hate math, I will still need to do my best to understand this chapter because I will need it in the future. Because of this, I decided to pick up my knowledge of linear algebra. The hands-on book gives me a checklist of things I need:
- Vectors
- Matrices
- How to transpose them
- How to multiply them
- How to inverse them
- I need to know what partial derivatives are
With this, I close the book Hands-On Machine Learning with Scikit-Learn & TensorFlow by Aurélien Géron on page 108. Then I went to the attic where I keep the books I bought when studying Computer Science at the Uni. I found I had Numerical Linear Algebra and Optimization Volume 1 by Philip E. Gill, Walter Murrey, and Margeret H. Wright. That will do for me.
When I ticked the entire checklist of Aurélien, I will go back to his book. There are 6 items to cover.
Now I hope that my Linear Algebra book uses the notation that Aurélien is using. Is there an ISO standard for mathematical notations? My linear algebra book was published in 1991. That is 28 years ago. My Hands-On book was published on April 19 this year. That is the thirteenth print of the first edition. Oh well, just move on and worry about other things.
I find it funny that you can do so much with arrays. So a vector is an array in a way with one column and n rows.
Look here is a table x where each cell is a scalar. This is a vector:
|
x1 |
|
x2 |
|
... |
|
xn |
Now I probably need to figure out how to detect subscript in my word parser. I will leave that as an exercise for my future self.
A vector is normally represented by a lowercase roman letter such as a, b, z, x, etc. This vector here above can be written as a.
The vector has n dimensions. When referring to one component in a vector, we use the subscript notation. A vector with n components is called an n-vector.
Two vectors are identical if they have the same dimension, and all components are identical in the same position.
The vector here above can be transposed, like so:
|
x1 |
x2 |
... |
xn |
This is also written as aT. Now my parser needs to handle superscript as well. If written in plain text, a vector with several rows are written separated with commas. How it is written does not matter so much to me because we will soon switch to Python or Json or whatever, but for now, this is what my book from 1991 is saying. We go with that.
Sometimes the row of a m x n matrix A is denoted as a'i where i is the row number.
On to something more complex. Addition of two n-vectors.
Suppose we have the vector y (the same dimension as the transposed x here above)
y=
|
y1 |
|
y2 |
|
... |
|
yn |
Then x + y is
|
x1 + y1 |
|
x2 + y2 |
|
... |
|
xn + yn |
We can only add vectors of the same dimension. Luckily.
Next up, we multiply an n-vector with a scalar. The result is that all components are multiplied with that scalar.
There is a special situation when multiplying with -1. When doing so, all values are changing sign. They say that two vectors have the same direction if x=uy where u is a nonzero scalar.
We skip the linear combination for now.
Then we got the inner product, also called the scalar product or dot product. It is a multiplication of two vectors of the same dimension. Like so:
xTy = x1y1 + x2y2 + ... + xnyn = Sum from 1 to n over xiyi. The order of products is retained.
The result may become zero. That was vectors, check! One done, six to go.
Next up are matrices. A matrix is two dimensional. Rows run from top to bottom. Columns run from left to right. A matrix is usually denoted with upper case roman letters. A matrix is m x n if it has m rows and n columns, hence mn elements. So here it is elements instead of components. Cool.
Two matrices have the same dimension if they have the same number of rows and columns. The book express this way more complex. Perhaps there is some profound difference in the language, but let us hope not.
A particular element in the matrix is denoted with the lower case version of the letter of the matrix with the row and column in subscript. I wonder how they do for more than 9 columns and rows? No idea. The rows and the columns are one-based, so the first row is 1 and so on.
So aii is the diagonal element of A.
When transposing a vector, we flip it around the aii diagonal.
A
|
1 |
2 |
-1 |
|
3 |
-4 |
6 |
Then AT is
|
1 |
3 |
|
2 |
-4 |
|
-1 |
6 |
That was transpose, check! Two done, four to go.
We can add two matrices of equal dimension. The result is a new matrix where each cell is the sum of the two at the same coordinate.
We can multiply a matrix with a scalar constant, giving a new matrix where all elements are multiplied with that scalar.
The multiplication of an m x n matrix A and an n - vector x is denoted by Ax. The dimension of x must be the same as the number of columns in A. The dimension of Ax is the same as the number of rows in A.
Sunday 22 September 2019
It is already Sunday morning. I have not worked on this ML/AI book for almost an entire week. There was much going on with preparing the permits of the house.
I just started reading in on the multiplication of vector and matrix. That is when the cool things start to happen with linear algebra. When talking about m x n vector A, it is the number of rows m coming first, followed by the number of columns n.
|
a11 |
a12 |
a13 |
|
a21 |
a22 |
a23 |
Then if we take a vector x with dimension n columns, like so:
|
x1 |
|
x2 |
|
x3 |
Then when the dimension of x has the same number of columns as A, then we can take the product of A and x. This is written Ax. This product produces a vector with the same number of rows as A has.
|
a11x1 + a12x2 + a13x3 |
|
a21x1 + a22x2 + a23x3 |
I write this table, but I cannot say I find it easy to remember. This is essentially a system of two-dimensional arrays and the manipulations of these arrays. There should not be much to it, but obviously, it becomes algorithms for how to manipulate them.
We are working us through the matrix A row by row. In each row, each column-calculation are added together. The column calculation is the product of that cell with the corresponding row in the vector x.
Here I had a break. I went to the opening of an art installation in a park. It was great weather. I had hoped I would meet another artist, but he doesn't stand noise, so he did not show up. Now it is already evening. I cannot say that learning linear algebra (again) is the funniest thing I could do on a Sunday evening. Here we go anyway.
This is why we will bring this complexity up a notch by multiplying a matrix with a matrix.
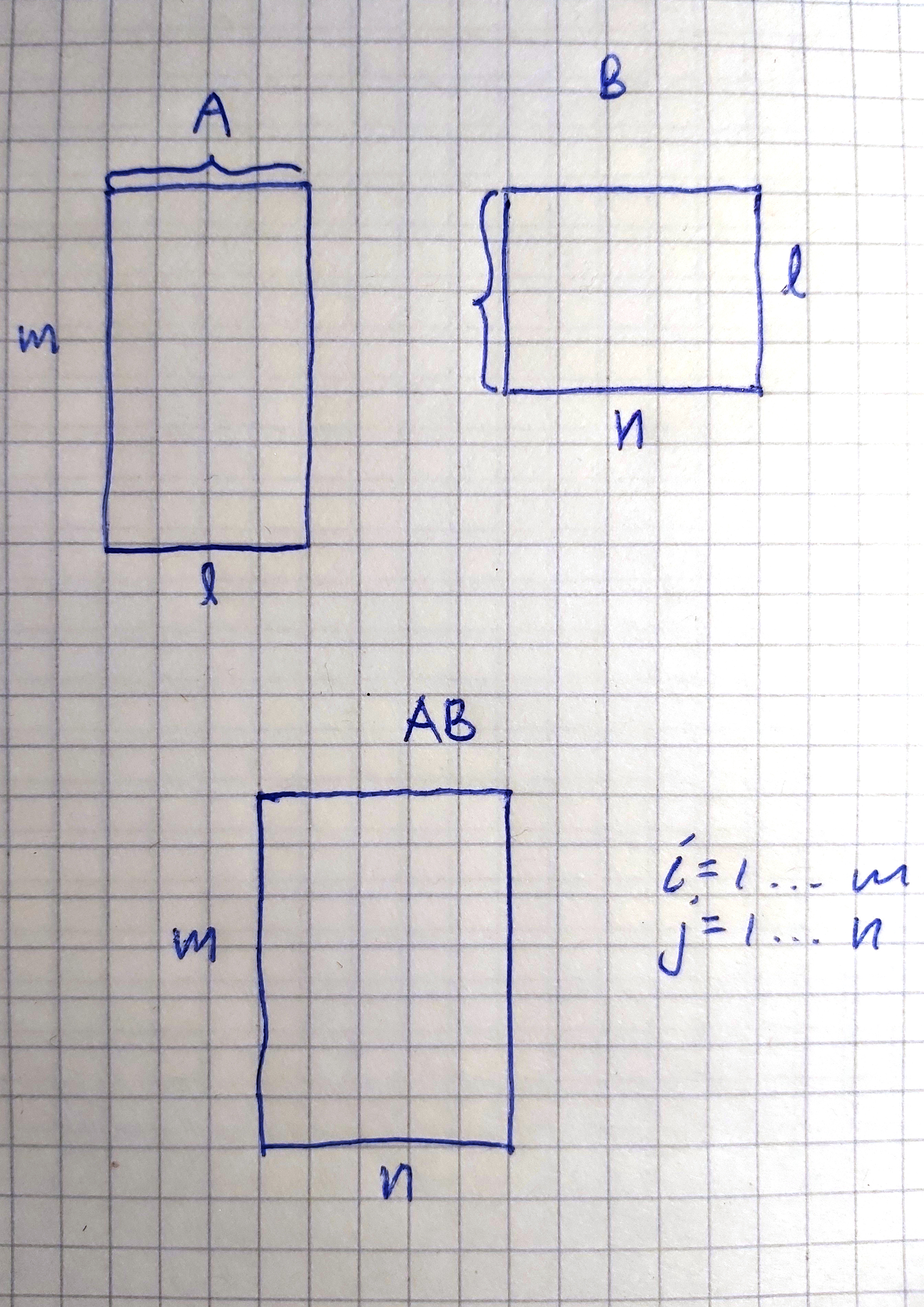
A times B denoted as AB is possible only if the column dimension of A is equal to the row dimension of B. If A is m x l and B is l x n, then AB is an m x n matrix whose (i,j) element is given by (AB)ij = Sum from k = 1 up to k = l of aikbkj where i is 1 .. m and j is 1 .. n. Totally cryptic.
First part first. So the number of columns of A needs to be equal to the number of rows of B. If not, it will not work. Simple as that. Let us talk about how we walk the to matrices.
Tuesday 23 September 2019
The thing doing the walk is the iteration over k. So k is 1 and then increased one by one up to l.
We walk the rows one by one of A from top to bottom. For each row, we walk the column from left to right.
The multiplication of A times B is denoted as (AB)ij. This describes every cell in the resulting matrix.
So we can take, for example, the second row and the third column of the AB matrix, and we look into how that cell is calculated. For this example, I take a cell with different indexes so that it is easier to see where the numbers got. The resulting cell would be (AB)23.
That will give a loop from 1 to l. In my case, my drawing had 4 squares for l. So it would be from 1 to 4.
This is the inner product added up: aikbkj. That means a2kbk3 because i was 2 and j was 3.
For this we get a series of multiplications added together: a21bk1 + a22bk2 + a23b33 + a24b43. I marked this with red.
Here is another example that I marked light blue: (AB)55 = a51b15 + a52b25 + a53b35 + a54b45.
Here is another example that I marked yellow: (AB)62 = a61b12 + a62b22 + a63b32 + a64b42.
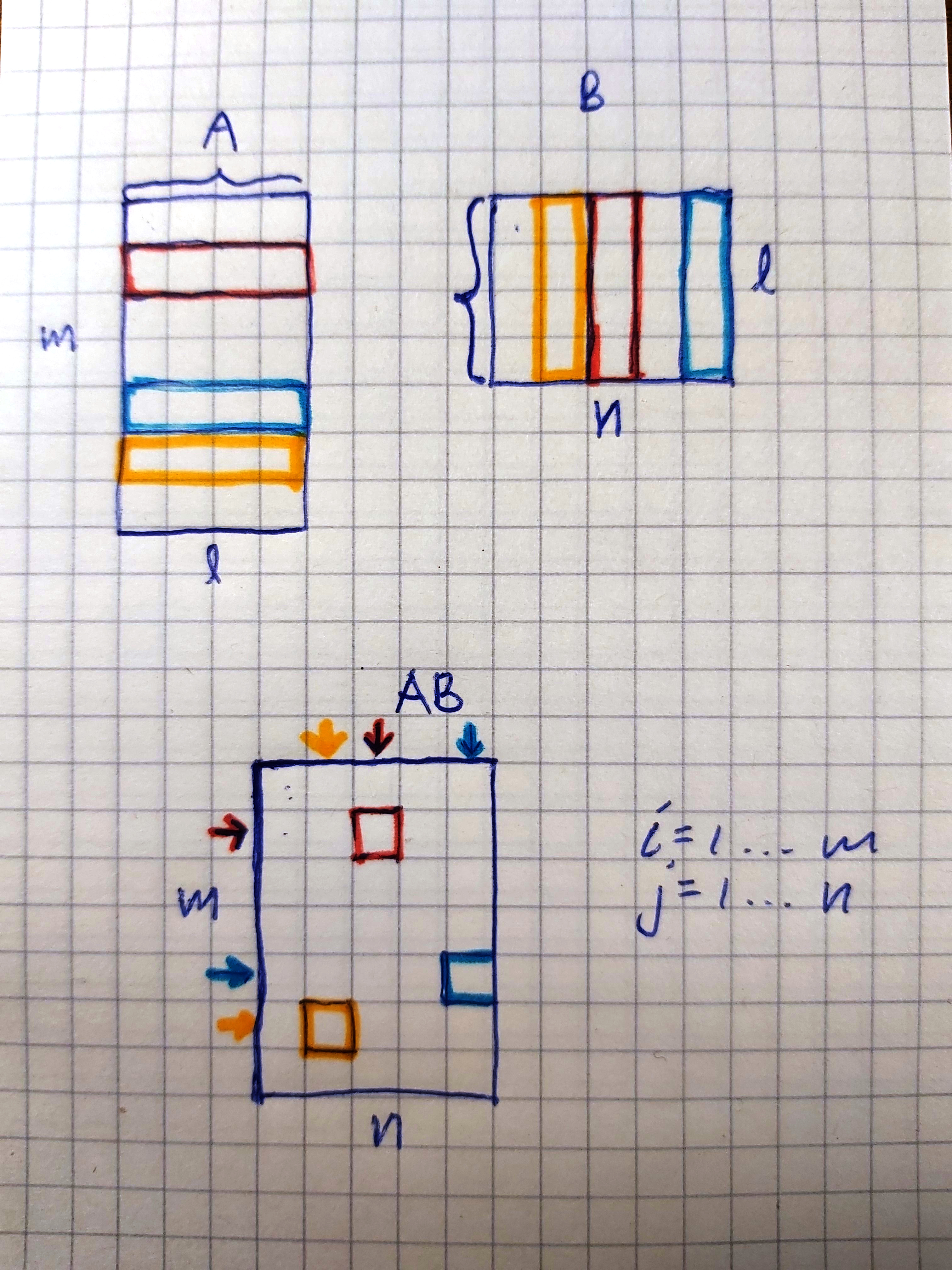
Obviously the algorithm calculating the result need to calculate all the cells.
With that, I handled the multiplication of matrices. In total, I covered 4 of 6 linear algebra todo items. The next item on the todo list is how to inverse matrices.
25 and 29 of September 2019
I am pondered over the book in Linear Algebra and concluded it would kill me if I went down with it without any "first aid kit."
Searched for people doing explanations of inverting matrices. Found a Khan Academy lecture with the hashtag #YouCanLearnAnything. Oh yeah! The person presenting this is Sal Khan:
The pixel quality of this YouTube movie is uh 240 pixels. That is not much, but besides that, it was nice to jump right on to inverting 3 by 3 matrices.
The person doing this presentation has a very pleasant voice.
This week international leaders came to the UN to talk about the climate. It was also a week when Greta held a speech at the UN. During this week, I arranged for taxation of the future building and received it at the end of the week. This means that we can continue on the application for a mortgage at the Bank next week. I also got a second-hand printer this week. It is installed, and it is working. I brought my old printer to the garbage collection point.
Back to linear algebra. When I read the introduction of matrices, I skipped the paragraph about the identity matrics. It is necessary for an understanding of the inversion.
An identity matrix is a square matric, and it has ones in the diagonal from the upper left corner going down to the lower right corner. The rest are zeros. In the matrix world, the identity matrix is kind of like the number one of regular mathematics. Multiplying a matrix with the identity matrix can look like this:
IA = A
AI = A
Direction matters for matrix multiplication.
In regular mathematics 1a = a and (1/a)a=1
We call 1/a the inverse of a. Is there a matrix analogy?
Is there a matrix where we multiply A inverse with A and that it becomes I? It is also written
A-1A=I
AA-1=I
Yes, that is true, there is such a matrix.
It is funny because of the Khan Academy talks about how to calculate the inverse of a 2 by 2 matrix, and my linear algebra book is also doing that.

In the evening, I found this video.
Another video from the Khan Academy. It was the AI algorithm of YouTube, suggesting this video. It was great.
I can see that my linear algebra book discourages me from calculating the inverse explicitly "by hand." The book is warning about this at several places. Now I have an understanding that there is an inverse, and I have seen Sal Khan calculate it, and it looks plausible enough. For now, I will keep to this level. So with that, I have a kind of understanding of what the inverse of a matrix is and how to use it. With that, I checked 5/6 of the todo list on linear algebra.
The final point is partial derivatives, but that is for next time.
Sunday 12 October 2019
Oh, dear, have I had slack in this project the last couple of weeks. I have studied this stuff, but I ended up deleting my blogging of it. I restarted a couple of times. What really saved me was Khan Academy. I have been busy with the house, as well.
To be able to understand partial derivatives, I had to go back and refresh my knowledge of derivatives. A good thing with this was that I actually recall studying this. Nevertheless, I went looking at Khan Academy YouTube movies about derivatives, how to calculate the slope of a function. Enjoyed these videos:
https://youtu.be/ANyVpMS3HL4 , https://youtu.be/IePCHjMeFkE , https://youtu.be/HEH_oKNLgUU , https://youtu.be/Df2escG-Vu0 , https://youtu.be/ePh8iCbcXfA
As a positive side note, I would like to say that the Khan Academy site is actually really good. There is a menu indicating where I was in the math universe, and I could traverse myself up in the tree to look over the landscape. Khan was using factorization of higher degree polynomials in a sample (rather casually), and indeed, that is something I did when I was younger. But I am old now and had no chance of using that stuff at work for twenty years, so it has become what rusty that knowledge. That is no problem because in this day and age you have the information at your fingertips. It is just a question of finding it. So I went back and had myself a touch upon the polynomial factorization. How cool is that?! It helps that Sal Khan has a pleasant voice. Haha.
Now with better self-confidence, I had a new go at looking into partial derivatives, the sixth todo from that Hands-On Machine Learn book by Aurelien Geron, do you remember? The only question was where to find it in all the Khan Academy pages. Ended up googling for "site: www.khanacademy.org partial derivatives," and there I found out that the thing I need to look at is embedded in the Multivariable calculus section.
https://www.khanacademy.org/math/multivariable-calculus
 Ooh, this section is made by Grant. He does not have an as pleasant voice as Sal Khan. As you know by now, I hate it if people don't present themselves, so I am very pleased to tell you that Grant presented himself! He likes presenting things graphically, and I like that a lot, so I will hang on in here and enjoy every bit of this.
Ooh, this section is made by Grant. He does not have an as pleasant voice as Sal Khan. As you know by now, I hate it if people don't present themselves, so I am very pleased to tell you that Grant presented himself! He likes presenting things graphically, and I like that a lot, so I will hang on in here and enjoy every bit of this.
Brain quota full. I have to sleep.
It is Sunday evening 13 October 2019
Yesterday we applied for becoming formal members of the road association, and we paid our part of the future road. It is complex. Essentially we are sending money to an organization that we just started, and it will buy the ground of the road of the part of the land that we have an option to buy. So the road association will buy the land under the road with our money, and we have not even got an okay for buying the land.
Today we went to the future plot to see how streams and canals are done around the area.
So that was all that. Now I am back to multivariable calculus. I decided to become a member of the Khan Academy as well. It turns out I get energy points for taking classes. No idea what that is, I will figure out later.
I started on viewing videos of transformations by Grant.
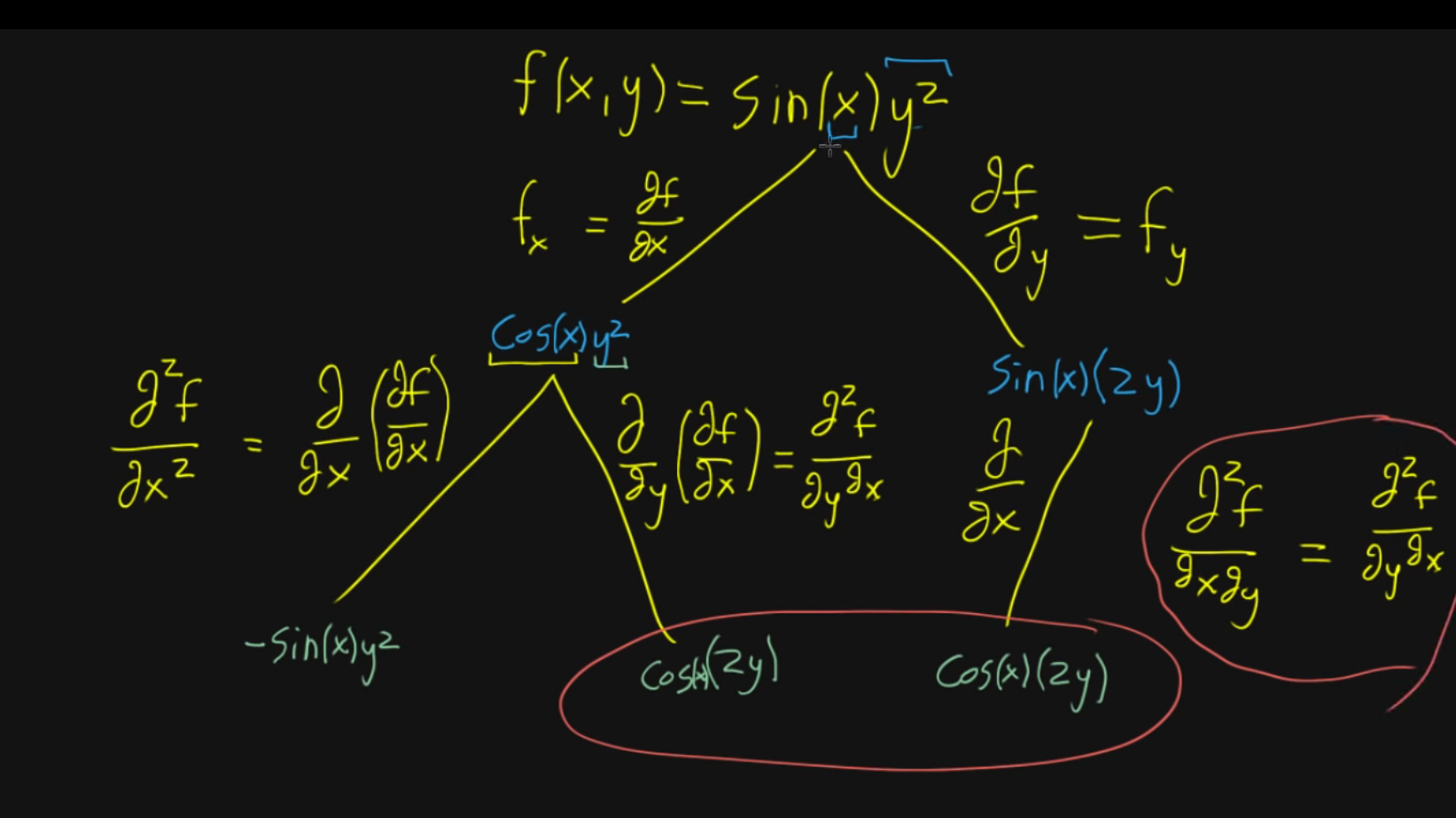
Wednesday 16 October 2019
Today we got a message from the bank. A positive message. I sent this to the municipality so that they can continue to process Bibob and the building permit. The deadline for the first eight-week section of the building permit is next Monday, so the message from the bank came terribly close to the deadline. I hold my hart.
When not working on the house, I watch Khan Videos about multivariable functions.
Sunday 20 October 2019
On Friday, we received a message from the building permit department of the municipality. It was actually an external company InterConcept doing the validation of the permit. They needed additional information. We worked the entire weekend, pulling the requested information together. On Monday, we will call them and ask for a small clarification, and then we can submit the new package. This time it became 20 documents with all sorts of documentation. I had no time working on learning AI and ML.
Sunday 27 October 2019
It is crazy how much time "got lost" in the house project the last week. I wrote about it in detail in a post from last Thursday, so I will not go into detail here. I am back, doing all the required stuff for now. Time for some quality time with the math.
One more side note, though. I missed the season start of the painting sessions at de Stoker. I will start attending that next Sunday.
Monday 28 October 2019
We were able to speak with our contact at the municipality, and it sounds like the issue with the datum is sorted. We got back the original 6 weeks extension. We could also explain how easy we made it for them to do the work by providing them with a summary of all the things they asked for pointing to each provided document.
With that out of the way, it is time to get back on this math stuff.
When I got into this math hiatus, I had been watching Grant talking about Gradient steepest ascent, the last video on that section.
In spare moments I got back, and I was confused about the structure of things. I had gotten used to listening to Grant in youtube videos. Then I got out of the series of Grant as a presenter, there was a series of documents summarizing the things Grant had been talking about. I was not under the impression that Sal would come back. I got surprised that after the documents, Sal came back. In fact, I was so surprised I went back to the videos by Grant to indeed see that they linked to documents, then that they linked to sal.
Here we arrived in the introduction to vector-valued functions.
Saturday 2 November 2019
It is already Saturday evening. This artificial intelligence stuff is gliding away out of my hands if I continue like this. This week was busy. On Wednesday, we had a meeting at the road association of the new housing area where we will build our house. There were presentations on what is going on. Road building companies have been contacted, and our association selected a company to build the road. We had a meeting with a company installing heating pump systems. We would like to have a system that takes the heat from the ground. No news on the building permits.
I viewed through the Sal videos and earned an Awesome Listener badge!

After that, Grant came back! https://youtu.be/NO3AqAaAE6o
Monday 4 November 2019
I am back!
Here we are getting into vector notation of multivariable partial derivatives.
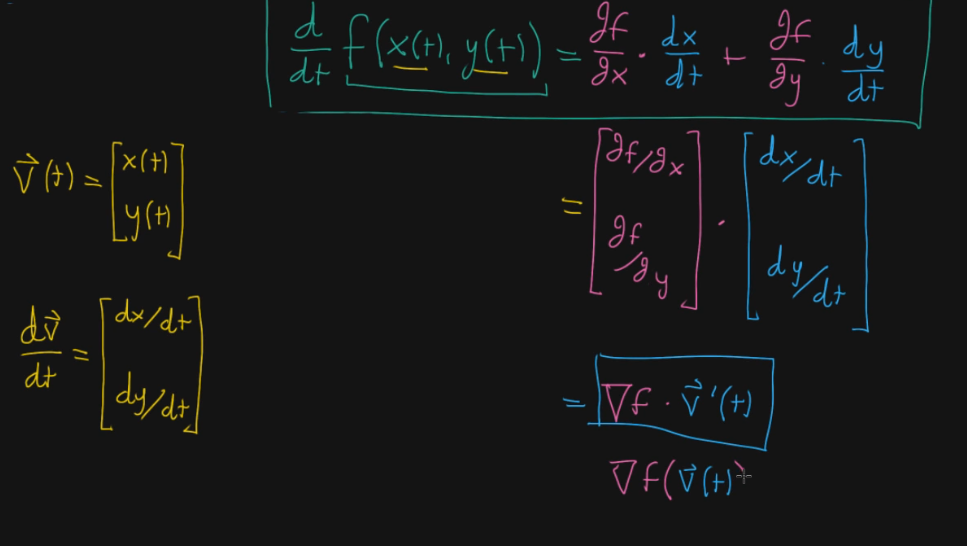
This has not landed. I am afraid I will need to go back and reiterate a big chunk of this.
Next up is Curvature.
https://www.khanacademy.org/math/multivariable-calculus/multivariable-derivatives#curvature
The curvature series is Grant's stuff. I was into movie 4 when I suddenly was asked to remember what the cross product is and if I missed that, I could stop the video and have a look. So I did just that.
I went to this video: https://youtu.be/pJzmiywagfY
This is a video by Sal with a nice voice. He explained that if you take the cross product of two vectors, you calculate the orthogonal vector. But then he said that there is a way of remembering in what direction the orthogonal vector is pointing, a rule of thumb. Literally. Then he went ahead, drawing a really beautiful hand. I am a painter, so I know how hard it is to make a drawing of such a hand. That is really cool. Is it not fantastic how he even made a thumb?


Now you are wondering if I will remember the cross product, but I can assure you that that will not happen. I will have to go back and refresh myself on the cross product every time I need it for the rest of my life.
After this conclusion, I hastily continued to look at the fourth video with Grant explaining the curvatures.
Tuesday, November 12, 2019
We had a setback for the house. The bank retracted the offer for a bank loan. The reason "We do not offer loans that require customization." Huh?
No news on the building permit. We need to fill in more information about the house for the road association because they will use that for starting up the electricity and water facilities.
I have been busy with blogging about paintings I am making. My paintings feel like they are going well.
So I am back into Artificial Intelligence and Machine Learning. Woohoo!
I am on the fifth video on the curvature after I had a detour to the cross product, and I forgot all of it.
Rather than feeling huge despair about the things I have not learned, I will now "graduate" myself from the detour into linear algebra. Perhaps you still remember, I am on the sixth todo point of the things I need to know. "I need to know what partial derivatives are." It was on the 16th of September. I closed the book I was reading "Hands-On Machine Learning with Scikit-Learn & Tensorflow" by Aurélien Géron and started picking up my linear algebra skills.
I am back on page 108. So let the fun begin.
Well, the first sentence is about things we looked at in the first chapter. I cannot remember that anymore. It is on page 18. Since I write about how I read the book, I could go back to my notes from the 18th of August, and it looks like I ripped up the package of the book and skimmed reading the first pages. On page 18, I was not paying attention to any θ (Letter "Theta"). Indeed there is a life satisfaction function in a simple linear model.
Thursday 14 November 2019
We had another setback for the house. We got a message from the municipality that a kind of bolt to be used is not properly dimensioned. The message was sent to us on 12 of November, but I did not see it. This morning I discovered the message and forwarded it to the building company. Later in the day, I called them, and the person who is doing their construction drawings was away from the office for two days. It is clear now we will not finish the permit before all the people at the municipality goes for the Christmas holidays. Maybe.
Tonight I should paint at the aquarelle club, but I came home late from work. Instead, I worked on a letter to the building company.
When that was finished, I started on the AI/ML study.
The book will explore ways to find a curve that goes through a set of points in the best possible way. At first, it is a linear line we will find. In a subsequent chapter, we will look into curvy lines.
First, I am reading about an equation the classic way, and then we are presented the same equation using vector notation. It is good that I practiced some linear algebra for a while now. The book kindly asks me to go and have a look at the notations page an page 38. They talk about the hat notation, a circumflex sign above a letter. Wikipedia also says it is a predicted value. Let's go with that.
There are two ways to find a solution. One is by solving the equation mathematically. Another by iterative optimization.
The mathematical way is done with an equation called the Normal Equation. It is a little hocus pocus. It calculates the theta prediction vector with ((X transposed times X) and this inversed) times X also transposed, and this time the vector y of target values. I recall taking the inverse of a vector in itself was hocus pocus and also computational heavy.
As expected, these calculations are crunched into Python. There is already an inversion function available. Essentially this book is just about entering already made examples of libraries that solve standard problems. Fine enough, it is good stuff anyway!
Saturday 16 November 2019
Continuing on page 111. I started Visual Studio Code, and I realized I forget even how to start the Python environment for the book.
- Select Open Folder in Visual Studio Code.
- Select Start Debugging.
- Enter the "jupyter notebook" in the terminal.
Wow cool. Now I will not forget that from now on.
On Github, the document for the book chapter 4 is found at this location: https://github.com/ageron/handson-ml/blob/master/04_training_linear_models.ipynb
This document had the figure saving routine at the beginning of the file (that I missed in earlier chapters). It was just one issue with the imaging routine, it did not have the proper directory to store the file. When I created that, I even got an image generated for me!
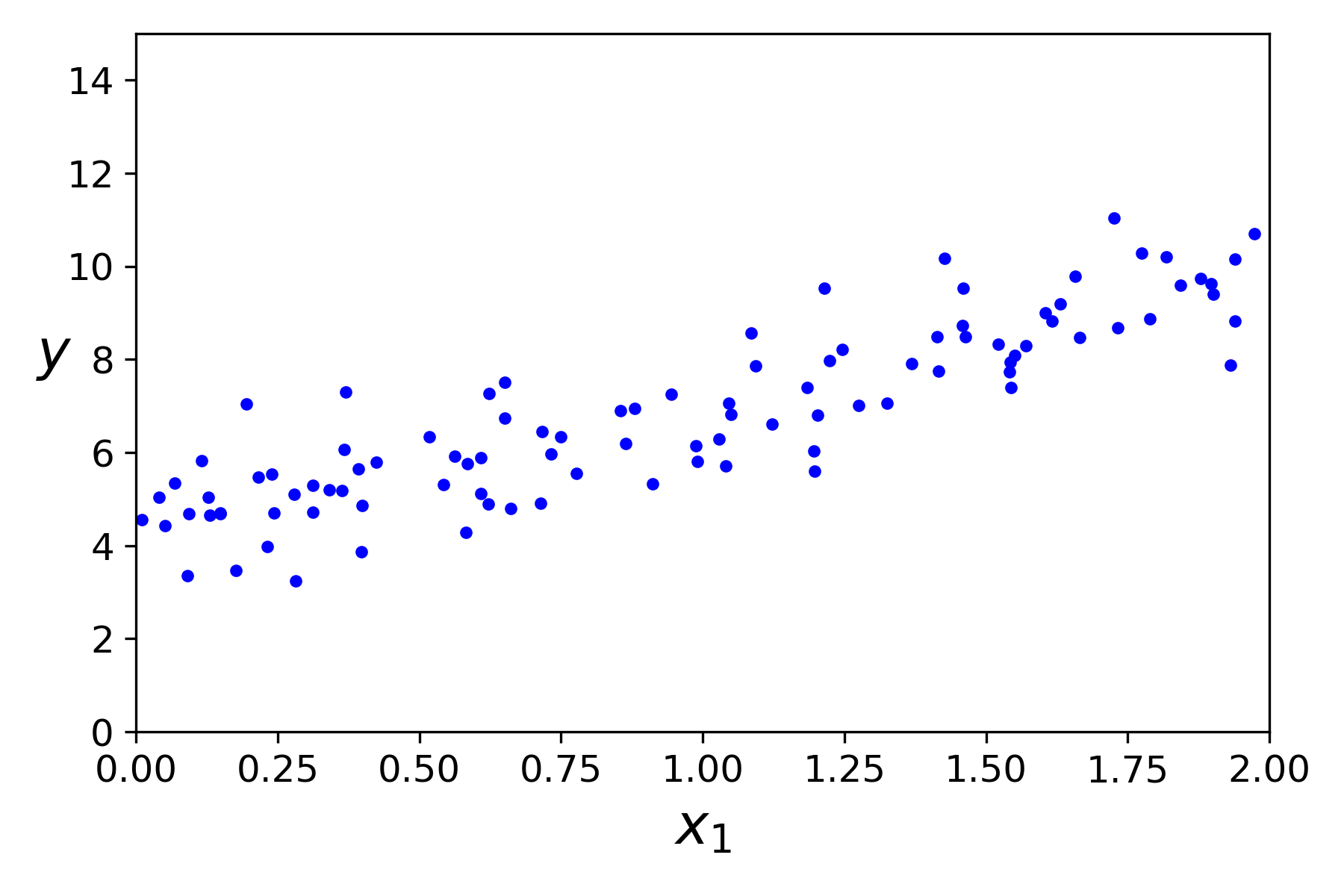
This is a random scatter of dots, and now we will find a line going through these dots. I. AM. EXCITED.
Both X and y are arrays of one hundred items each.
This is getting complicated quickly. So the first line is "X_b = np.c_[np.ones((100, 1)), X]". Of this is this part creating an array with only ones in it: "np.ones((100, 1))". Hundred lines one column. Then "np.c_[np.ones((100, 1)), X]" combines the hundreds of ones with the X array, and the result is a new array with two columns. The first column is the ones, and the second is the values from the X array.
The next calculation is this: "theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)". In this "X_b.T" transposes the array. Dot is doing a linear algebra dot multiplication. This is just the python function for the formula 4-4. 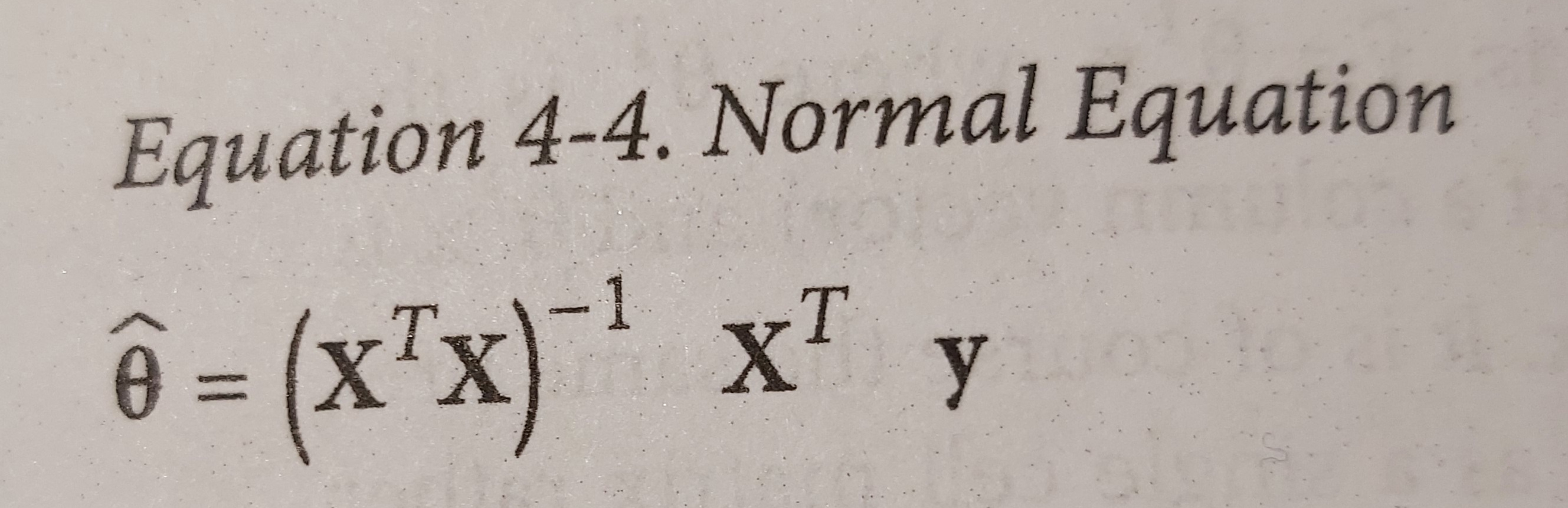
That is cool actually that the formula is matching the Python code in such a nice way. What is happening, I don't know, but it looks cool.
Sunday 17 November 2019
I have some spare time over, so I will do some AI/ML. Today I went painting Eivor as well, but I am blogging about that in a separate post.
Yesterday I learned that NumPy implements linear algebra really good. It is just a question about how things are called, and then you can let Python calculate. To this, they added helper functions that transpose and all sorts of things.
It feels like if I fail to understand this ML/AI at some point, I can always go back to Khan Academy and redo the lessons but run the calculations in parallel using NumPy. For now, I push on.
Ok, I recap for myself. We generate random test data.
![]()
This is to say that X in a matrix of 100 values ranging from 0 to 2. I can see that as the x-axis in the diagram, and it looks like so from the formula. The "y" formula is more complex. I will need to break up the formula in steps. 3 * X generates a vector where the X values are all multiplied by 3. Then adding 4. Then on top of that, adding a random value from -1 to 1 for all X values in the vector. With this, I understand that we get scattered points starting at around 4 and ending somewhere around 4+3*2 + random value plus/minus one.
The point is that we will use the Normal Equation formula to predict this.
![]()
Although this is still abracadabra, out from this function comes theta_best. If you are like me, you probably forgot what they said on page 18 that you read a couple of months ago.
So theta0 is found to be 4.21509616 in our diagram, and theta1 is 2.77011339. The result is in this array form:
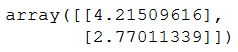
Two rows and one column.
Monday 18 November 2019
After staring for a good while at the algorithm for life satisfaction on page 18, I realize that theta0 and theta1 have the same function as we have it in our randomly generated graph. It is used to describe a line.
The next thing the book is doing is to calculate the height of the beginning of the predicted line at zero and then at the end at two. They do this with linear algebra and NumPy. I feel that this is not of huge value for learning ML/AI, but I will try to understand every piece of it because that is probably the kind of thing there will be more of.
This is how the book calculated the two values:

They create an array called X_new. This is done with the NumPy.array method. It looks impressive, but the result is just an array with one column with two rows. I played around with this method for a while, and I found that if you feed it with an irregular shape. Let's say you got three rows, and each row has 2 items, except the last row because it got three, then you get all rows as lists. In our case, such a small array with two rows and one column, I wonder why they could not enter it manually. Is it because they want us to go find out what is happening, or do they want to be posh?
Anyhow if you call the shape method of an array, then you will be given the number of rows and columns (in that order). I have not yet figured out how it works with more dimensions.
On the next line, they create an array with two rows and one column filled with ones. That is then combined with the previous array so that we get two columns and two rows.
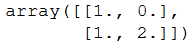
This is assigned to X_new_b
Then they take X_new_b dot product with theta_best. Oh dear, now I need to remember the dot product.
so a dot b is a time bT.
X_new_b is:
|
1 |
0 |
|
1 |
2 |
And theta_best transposed is:
|
4.21 |
|
2.77 |
1x4.21 + 0x2.77 = 4.21
1x4.21 + 2x2.77 = 9.75
Found a calculator showing these calculations in detail: https://matrix.reshish.com/multCalculation.php
Saturday 23 November 2019
I am currently on page 111. Last Monday, I looked into the prediction of a line. Now I got to plot the prediction.
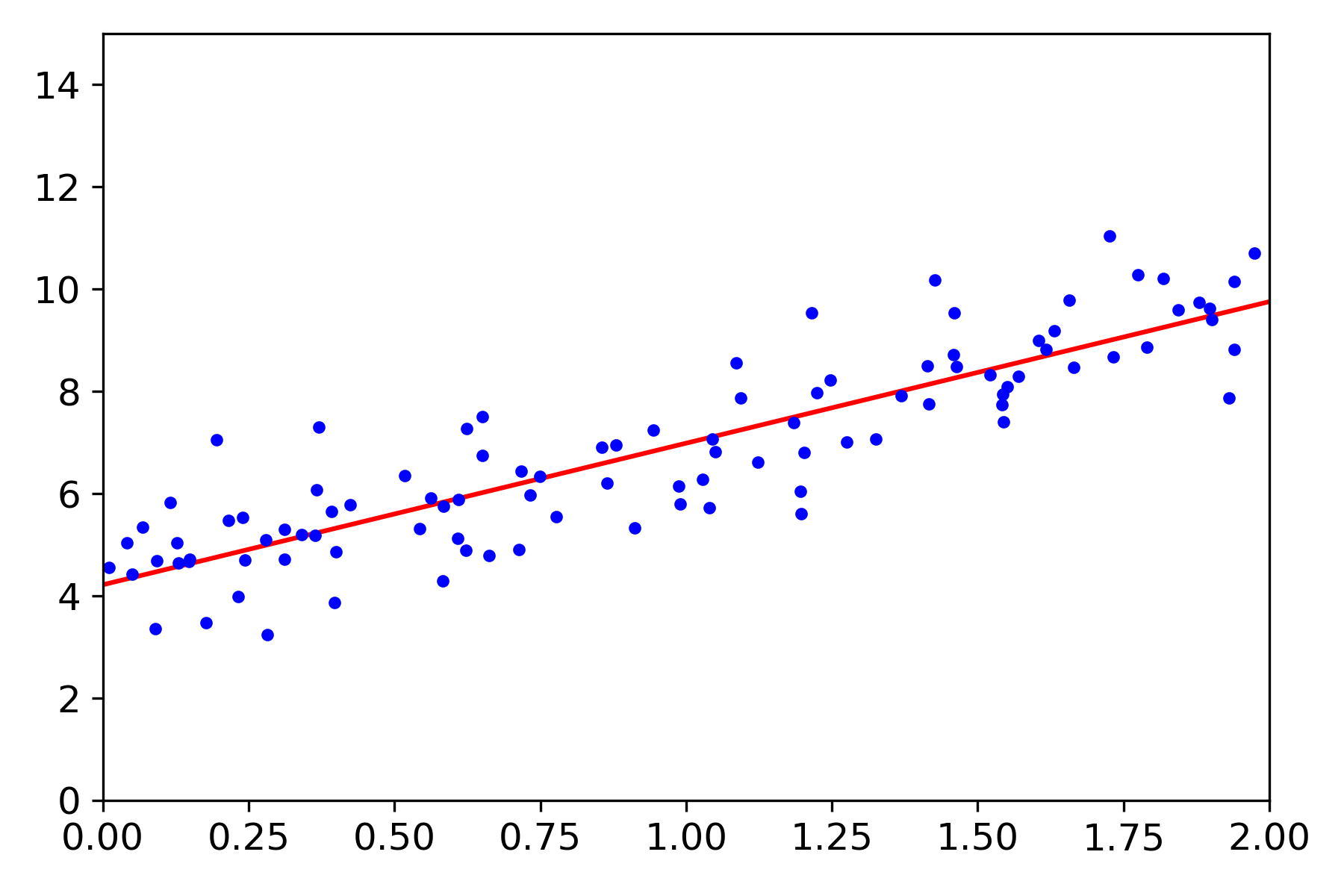
I finally looked into the plot function, how that works. This code was given by the book.

The plotting functionality is based on matplotlib. I searched for it and found an explanation of what it is doing. The first two arguments are arrays of data. The third argument explains how to paint that data. "r-" is a solid red line and "b." are blue dots.
Added a line causing the figure to be saved to a file.
When I studied linear algebra at Khan Academy, they said that inversions are expensive operations. This is also what the book is saying. They give other methods to make predictions in a less computation-heavy way.
The Normal Equation is ordo n to the power of 2.4 up to ordo n to the power of 3. The Single Value Decomposition method is ordo n to the power of 2, and that is cheaper.
Next up on page 113, we start talking about Gradient Descent. This is another method for linear regression. Here follows a couple of pages with big images talking about how Gradient Descent can find minimum values of a graph.
In the section Batch Gradient Descent on page 117, we are getting near the things I learned at Khan Academy.

This is complicated math. I recognize this from Khan Academy. Partial derivatives to find how graphs are sloping.
The math here is costly, so I will not dig deep into this how it is working.
In the next section on page 120, we start to read about Stochastic Gradient Descent. Now we are talking, this is useful. The word stochastic is originally from Greek, where it meant "to aim" or "guess." A process that is randomly determined is also called stochastic. These terms are used interchangeably.
The previous model used the entire test set to calculate the gradient. In this model for each iteration, only a randomly picked instance is used to calculate the gradient.
The random nature of this method is both the strength of the method but also its weakness. The book explains that when it is stopped abruptly, it might not be at the optimal point but bouncing around.
The book talks about ways of creating a learning schedule. On page 121, an algorithm is given for how this could be used. I skip it.
On page 122, we are presented with a hybrid between the previous two methods. It is called Mini-batch Gradient Descent.
At this point, this book is switching from finding straight-line solutions to look into polynomial regression. For this, I decided to start the next part of this journey. I will upload this blog-post and then start on part 4.
But wait a moment. There is a catch! In this blog-post, I used subscript and superscript, and I placed images in the text without aligning them. I will need to adjust my word parser to handle these things before this can be published.
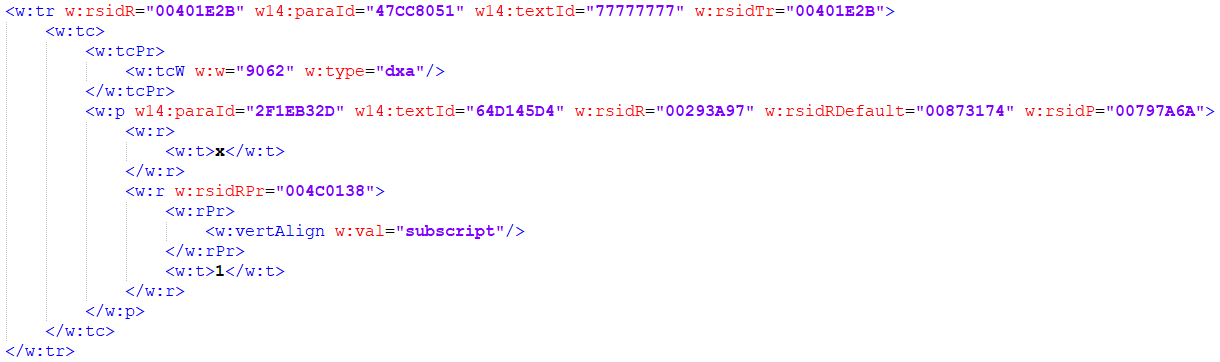
The first subscript on this page is something I wrote about on September 16. In a table there was x with a subscript 1. That looks like this in XML of the word document:
November 26, 2019
I changed the program to identify the subscript and the superscript. I also made it so that it displays a dialogbox that it has finished the export!
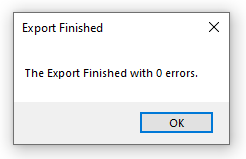
With that I am done with episode three of my jurney into learning Machine Learning and Artificial Intelligence.
Here below the full listing of my Python program exporting Images and resizing them and generating the html.
November 30, 2019
I noticed that my export program missed headings. That was not nice. So that is fixed. It could also not handle if a document ended with a list. All that is fixed now.
import docx
import os
import lxml
import xml
from io import StringIO,BytesIO
import zipfile
import sys
import cv2
import zlib
import docx.table
import codecs
import html
import ctypes
import xml.etree.ElementTree as ET
if len(sys.argv) != 2:
print("Please only call me with one parameter")
sys.exit()
iNumberOfErrors = 0
strInParaList = '' # '' = No List, 'bullet' = Bullet, 'decimal' = Decimal
iInParaListLevel = -1
bInParaStyleHeading2 = None
bInParaStyleCode = None
bPrevParaInStyleCode = None
bRunInStyleCode = None
bInRunBold = None
bInRunItalic = None
bInRunSubscript = None
bInRunSuperscript = None
strWordFile = sys.argv[1]
doc_DocX = docx.Document(strWordFile)
doc_ZipFile = zipfile.ZipFile(strWordFile, 'r')
ns = {
'w': 'http://schemas.openxmlformats.org/wordprocessingml/2006/main',
'a': 'http://schemas.openxmlformats.org/drawingml/2006/main',
'wp': 'http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing'
}
dictNumIDToAbstractNum = {}
dictNumAbstractIDToStrFormat = {}
dictListFormatToHtml = { 'bullet': 'ul', 'decimal': 'ol', 'upperRoman' : 'ol'}
for _FileInZip in doc_ZipFile.filelist:
if (_FileInZip.filename == "word/numbering.xml"):
fpNumbering = doc_ZipFile.open("word/numbering.xml")
numbering_Xml = ET.parse(fpNumbering)
num_Lst = numbering_Xml.findall("./w:num", ns)
for num_Element in num_Lst:
iNumId = int(num_Element.attrib['{http://schemas.openxmlformats.org/wordprocessingml/2006/main}numId'], 10)
AbstractNum_Element = num_Element.find("w:abstractNumId", ns)
iAbstractNumId = int(AbstractNum_Element.attrib['{http://schemas.openxmlformats.org/wordprocessingml/2006/main}val'], 10)
dictNumIDToAbstractNum[iNumId] = iAbstractNumId
numAbstract_Lst = numbering_Xml.findall("./w:abstractNum", ns)
for numAbstract_Element in numAbstract_Lst:
iAbstractNumId = int(numAbstract_Element.attrib['{http://schemas.openxmlformats.org/wordprocessingml/2006/main}abstractNumId'], 10)
AbstractNumLevel0Format_Element = numAbstract_Element.find("w:lvl[@w:ilvl='0']/w:numFmt", ns)
strFormat = AbstractNumLevel0Format_Element.attrib['{http://schemas.openxmlformats.org/wordprocessingml/2006/main}val']
dictNumAbstractIDToStrFormat[iAbstractNumId] = strFormat
fpStyles = doc_ZipFile.open("word/styles.xml")
styles_Xml = lxml.etree.parse(fpStyles)
style_Lst = styles_Xml.xpath("/w:styles/w:style[(@w:type='paragraph' or @w:type='character') and @w:customStyle='1']", namespaces=ns)
dictStyleIDLinkToOtherStyle = {}
for style_Element in style_Lst:
strStyleId = style_Element.attrib['{http://schemas.openxmlformats.org/wordprocessingml/2006/main}styleId']
linkToOtherStyleNode = style_Element.xpath("w:link/@w:val", namespaces=ns)
if (len(linkToOtherStyleNode) ≻ 0):
dictStyleIDLinkToOtherStyle[strStyleId] = linkToOtherStyleNode[0]
strBaseDir = os.path.dirname(strWordFile)
os.chdir(strBaseDir)
strBaseName = os.path.basename(os.path.splitext(strWordFile)[0])
def AnalyzeStateChangesInRunProduceMarkup(run):
"""Compare a run with the state, produce markup"""
global bInRunBold
global bInRunItalic
global bInRunSubscript
global bInRunSuperscript
global bRunInStyleCode
strMarkup = ""
if(run.bold != bInRunBold):
if(run.bold):
strMarkup += "≺strong≻"
bInRunBold = True
else:
strMarkup += "≺/strong≻"
bInRunBold = None
if(run.italic != bInRunItalic):
if(run.italic):
strMarkup += "≺em≻"
bInRunItalic = True
else:
strMarkup += "≺/em≻"
bInRunItalic = None
if (bInRunSubscript and run._r.rPr == None):
strMarkup += "≺/sub≻"
bInRunSubscript = None
else:
if (run._r.rPr != None and run._r.rPr.subscript != None):
if (run._r.rPr.subscript != bInRunSubscript):
if (run._r.rPr.subscript):
strMarkup += "≺sub≻"
bInRunSubscript = True
else:
strMarkup += "≺/sub≻"
bInRunSubscript = None
if (bInRunSuperscript and run._r.rPr == None):
strMarkup += "≺/sup≻"
bInRunSuperscript = None
else:
if (run._r.rPr != None and run._r.rPr.superscript != None):
if (run._r.rPr.superscript != bInRunSuperscript):
if (run._r.rPr.superscript):
strMarkup += "≺sup≻"
bInRunSuperscript = True
else:
strMarkup += "≺/sup≻"
bInRunSuperscript = None
if ('Code' == run.style.style_id or (dictStyleIDLinkToOtherStyle.__contains__(run.style.style_id) and dictStyleIDLinkToOtherStyle[run.style.style_id] == 'Code')):
bRunInStyleCode = True
else:
bRunInStyleCode = None
return strMarkup
def EndOngoingRunMarkup():
"""End ongoing runs, produce markup"""
global bInRunBold
global bInRunItalic
global bRunInStyleCode
global bInRunSuperscript
global bInRunSubscript
strMarkup = ""
if(bInRunItalic):
strMarkup += "≺/em≻"
bInRunItalic = False
if(bInRunBold):
strMarkup += "≺/strong≻"
bInRunBold = False
if (bInRunSubscript):
strMarkup += "≺/sub≻"
bInRunSubscript = False
if (bInRunSuperscript):
strMarkup += "≺/sup≻"
bInRunSuperscript = False
return strMarkup
def ProduceMarkupOfRun(current_Run):
"""This function produces the markup of a run"""
global bInParaStyleCode
global bRunInStyleCode
strMarkup = ""
if len(current_Run.element.drawing_lst) ≻ 0:
for drawing_Element in current_Run.element.drawing_lst:
anchor_Element = list(drawing_Element)[0]
graphic_Element = anchor_Element.find('a:graphic', ns)
strAlign = ""
if (list(drawing_Element)[0].tag ==
"{http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing}anchor"):
anchor_Element = list(drawing_Element)[0]
positionH_Element = anchor_Element.find("wp:positionH", ns)
strRelativeFrom = positionH_Element.attrib["relativeFrom"]
if (strRelativeFrom == "column"):
align_Element = positionH_Element.find("wp:align", ns)
strAlign = align_Element.text
strImageId = graphic_Element.graphicData.pic.blipFill.blip.embed
image_Rel = doc_DocX.part.rels[strImageId]
strImageTgt = image_Rel._baseURI[1:] + "/" + image_Rel.target_ref
ZipInfo = doc_ZipFile.NameToInfo[strImageTgt]
strFileNameOriginalSize = strBaseName + "_" + os.path.basename(ZipInfo.filename)
strFileNameResized = os.path.splitext(strFileNameOriginalSize)[0] + "~1" + os.path.splitext(strFileNameOriginalSize)[1]
ZipInfo.filename = strFileNameOriginalSize
doc_ZipFile.extract(ZipInfo, strBaseName)
iW = 400.
imgOrig = cv2.imread(strBaseDir + "" + strBaseName + "" + strFileNameOriginalSize)
iHeight, iWidth, iDepth = imgOrig.shape
fImgScale = iW/iWidth
iNewX,iNewY = imgOrig.shape[1]*fImgScale, imgOrig.shape[0]*fImgScale
imgResized = cv2.resize(imgOrig,(int(iNewX),int(iNewY)),cv2.INTER_AREA)
cv2.imwrite(strBaseDir + "" + strBaseName + "" + strFileNameResized, imgResized)
paragraph_Element.add_run(ZipInfo.filename)
strFloat = ''
if (strAlign != ''):
strFloat = " float:" + strAlign + ";"
strMarkup += "≺a href="/media/{0}" target="_blank"≻ ≺img height="{1}" src="/media/{2}" style = "margin: 5px;{3}" width="400" /≻≺/a≻".format(strFileNameOriginalSize, round(iNewY), strFileNameResized, strFloat)
strRunMarkup = AnalyzeStateChangesInRunProduceMarkup(current_Run)
if (strRunMarkup != ""):
strMarkup += strRunMarkup
if (bInParaStyleCode or bRunInStyleCode or bPrevParaInStyleCode):
strMarkup += html.escape(current_Run.text)
else:
strMarkup += current_Run.text
return strMarkup
def ParseParagraphChildElement(paragraphChild_Element):
"""This function parse the childs of a paragraph like runs etc"""
global iNumberOfErrors
strMarkup = ""
if (paragraphChild_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}hyperlink'):
strMarkup += ProduceMarkupOfHyperlink(paragraphChild_Element)
elif (paragraphChild_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}r'):
run = docx.text.run.Run(paragraphChild_Element, doc_DocX)
strMarkup += ProduceMarkupOfRun(run)
elif (paragraphChild_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}bookmarkStart'):
pass
elif (paragraphChild_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}bookmarkEnd'):
pass
elif (paragraphChild_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}pPr'):
pass
elif (paragraphChild_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}proofErr'):
pass
else:
iNumberOfErrors = iNumberOfErrors + 1
raise Exception("Unknown child element of paragraph")
return strMarkup
def ProduceMarkupOfHyperlink(hyperlink_Element):
"""This function produce the markup of a hyperlink element"""
link_id = hyperlink_Element.attrib['{http://schemas.openxmlformats.org/officeDocument/2006/relationships}id']
image_Rel = doc_DocX.part.rels[link_id]
image_Rel.target_ref
strMarkup = "≺a href = "{}"≻".format(image_Rel.target_ref)
for paragraphChild_Element in list(hyperlink_Element):
strMarkup += ParseParagraphChildElement(paragraphChild_Element)
strMarkup += "≺/a≻"
return strMarkup
def ProduceMarkupOfParagraph(paragraph_Element):
"""Parse a paragraph and produce the markup for it"""
strMarkup = ""
global strInParaList
global iInParaListLevel
global bRunInStyleCode
global bInParaStyleCode
global bPrevParaInStyleCode
global bInParaStyleHeading2
strHeadingNumber = ""
# All elements that spans over several paragraphs, such as Code, needs to be
# handled such that the end is detected in the next paragraph not having the
# same settings.
# For paragraph settings spanning over a paragraph the beginning takes place
# here and the end in the end of this function.
if (paragraph_Element.style.style_id == "Code"):
if (not(bPrevParaInStyleCode)):
strMarkup += "≺pre≻"
elif (bPrevParaInStyleCode):
strMarkup += "≺/pre≻"
# No else here because ending of code is additional to style of this paragraph
if (paragraph_Element.style.style_id[0:7] == "Heading"):
strHeadingNumber = paragraph_Element.style.style_id[7:]
strMarkup += "≺h" + strHeadingNumber + "≻"
elif (paragraph_Element._p.pPr != None and paragraph_Element._p.pPr.numPr != None):
iNumId = paragraph_Element._element.pPr.numPr.numId.val
iCurrentListLevel = paragraph_Element._element.pPr.numPr.ilvl.val
iAbstractId = dictNumIDToAbstractNum[iNumId]
strListFormat = dictNumAbstractIDToStrFormat[iAbstractId]
if (strInParaList != ''):
if (iCurrentListLevel ≻ iInParaListLevel):
#Higher list level
for i in range(iInParaListLevel, iCurrentListLevel):
strMarkup += "≺" + dictListFormatToHtml[strInParaList] + "≻"
elif (iCurrentListLevel ≺ iInParaListLevel):
#Lower list level
for i in range(iInParaListLevel, iCurrentListLevel, - 1):
strMarkup += "≺/" + dictListFormatToHtml[strInParaList] + "≻"
strMarkup += "≺li≻"
else:
strInParaList = strListFormat
# from -1 to 0
for i in range(iInParaListLevel, iCurrentListLevel):
strMarkup += "≺" + dictListFormatToHtml[strInParaList] + "≻"
strMarkup += "≺li≻"
iInParaListLevel = iCurrentListLevel
elif (strInParaList != ''):
for i in range(iInParaListLevel, -1, -1):
strMarkup += "≺/" + dictListFormatToHtml[strInParaList] + "≻"
strInParaList = ''
iInParaListLevel = -1
# List ended. Start para
strMarkup += "≺p≻"
elif (bPrevParaInStyleCode or paragraph_Element.style.style_id == "Code"):
strMarkup += "
"
else:
strMarkup += "≺p≻"
# This is the central part of this function.
# Here are runs parsed.
for paragraphChild_Element in list(paragraph_Element._element):
strMarkup += ParseParagraphChildElement(paragraphChild_Element)
else:
strMarkup += EndOngoingRunMarkup()
# Here is the end of parsing the paragraph. This part is
# has the same structure as the first part of this function
# i.e. change there equals change here.
if (paragraph_Element.style.style_id == "Code"):
bPrevParaInStyleCode = True
else:
bPrevParaInStyleCode = False
if (paragraph_Element.style.style_id[0:7] == "Heading"):
strHeadingNumber = paragraph_Element.style.style_id[7:]
strMarkup += "≺/h" + strHeadingNumber + "≻"
else:
if (paragraph_Element._p.pPr != None and paragraph_Element._p.pPr.numPr != None):
strMarkup += "≺/li≻"
else:
strMarkup += "≺/p≻"
return strMarkup
def ProduceMarkupOfTable(table_Element):
"""Parse a table and produce the markup for it"""
global iNumberOfErrors
strMarkup = "≺table≻"
for tableRow in list(table_Element.rows):
strMarkup += "≺tr≻"
for tableCell in tableRow.cells:
strMarkup += "≺td≻"
for child_Element in list(tableCell._element):
if (child_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}tbl'):
tableChild_Element = docx.table.Table(child_Element, doc_DocX)
strMarkup += ProduceMarkupOfTable(tableChild_Element)
elif (child_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}p'):
paragraph_Element = docx.text.paragraph.Paragraph(child_Element, doc_DocX)
strMarkup += ProduceMarkupOfParagraph(paragraph_Element)
elif (child_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}tcPr'):
pass # Ignore
else:
iNumberOfErrors = iNumberOfErrors + 1
raise Exception("Unknown child element {}".format(child_Element.tag))
strMarkup += "≺/td≻"
strMarkup += "≺/tr≻"
strMarkup += "≺/table≻"
return strMarkup
if not os.path.exists(strBaseDir + "" + strBaseName):
os.mkdir(strBaseDir + "" + strBaseName)
file = codecs.open(strBaseDir + "" + strBaseName + "" + strBaseName + ".htm", "w", "utf-8")
file.write(u'ufeff')
for child_Element in doc_DocX.element.body:
if (child_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}tbl'):
table_Element = docx.table.Table(child_Element, doc_DocX)
file.write(ProduceMarkupOfTable(table_Element))
elif (child_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}p'):
paragraph_Element = docx.text.paragraph.Paragraph(child_Element, doc_DocX)
file.write(ProduceMarkupOfParagraph(paragraph_Element))
elif (child_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}sectPr'):
pass
elif (child_Element.tag == '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}bookmarkEnd'):
pass
else:
iNumberOfErrors = iNumberOfErrors + 1
raise Exception("Unknown child element {}".format(child_Element.tag))
strMarkup = ""
if (strInParaList != ''):
for i in range(iInParaListLevel, -1, -1):
strMarkup += "≺/" + dictListFormatToHtml[strInParaList] + "≻"
if (bPrevParaInStyleCode):
strMarkup += "≺/pre≻"
file.write(strMarkup)
file.close()
del doc_DocX
ctypes.windll.user32.MessageBoxW(0, "The Export Finished with " + str(iNumberOfErrors) + " errors.", "Export Finished", 0)
## Styles:
## 0 : OK
## 1 : OK | Cancel
## 2 : Abort | Retry | Ignore
## 3 : Yes | No | Cancel
## 4 : Yes | No
## 5 : Retry | No
## 6 : Cancel | Try Again | Continue














 I moved from Sweden to The Netherlands in 1995.
I moved from Sweden to The Netherlands in 1995.
Here on this site, you find my creations because that is what I do. I create.